Plotting discrimination thresholds in TensorFlow
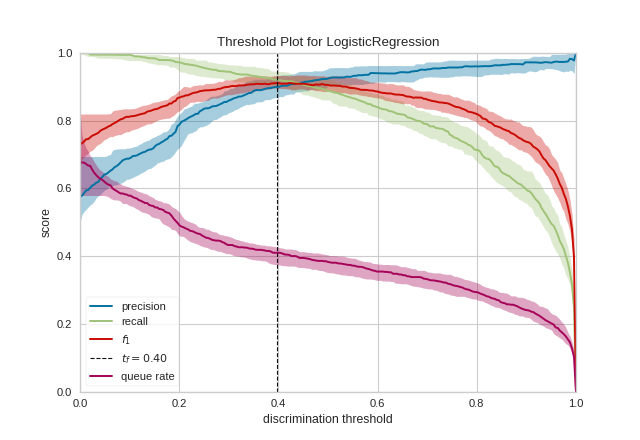
scikit-learn can render precision, recall and F1 score depending on thresholds in a chart. I wanted the same to evaluate my binary classifier made with TensorFlow. See how it looks like on scikit-learn.
O(data × number of thresholds)
Generating thresholds
In order to implement it, I had to figure out a few numpy tricks. First generating the thresholds. range only works for integers, so range(0, 1, .1) will simply raise an Exception. Numpy however provides linspace, which is what I was looking for: np.linspace(0, 1, number_of_thresholds).
Computing true positives, true negatives...
Second, computing true positives, true negatives, etc. A true positive is an input that the model predicted as being positive, and it is indeed positive. So if predictions is the batch of predictions, and labels is the batch of labels, true positives is the number of positive predictions that match the labels. In imperative programming you could write it like this:
true_positives = 0
for index, prediction in enumerate(predictions):
if prediction == y_batch[index]:
true_positives += 1
But you can do this more succinctly in Numpy using Boolean array indexing:
true_positives += np.sum(predictions[labels==1])
What it does is create a sub-array of predictions for when the element was actually positive. Then sum it up to find out how many of the predictions were positive as well.
Handling NaN values
One issue I encountered is when the model doesn't predict anything. As a result it divides by zero and NaNs occur. A better value would be to set it to 1, which you could interpret as "out of everything it predicted (ie nothing), it was right".
precision = true_positives / (true_positives + false_positives)
# Interpret NaN as perfect precision.
precision[np.isnan(precision)] = 1Writing the main loop
My initial implementation looked roughly like this. I removed a lot of the code just to show the gist of it:
def compute_metrics(model, validation_generator, threshold):
steps_per_epoch = validation_generator.n / validation_generator.batch_size
thresholds = np.linspace(0, 1, 11)
...
for i in range(len(validation_generator)):
x_batch, y_batch = validation_generator[i]
# collect true_positives, true_negatives...
...
accuracy = (true_positives + true_negatives) / everything
precision = true_positives / (true_positives + false_positives)
recall = true_positives / positives
return (accuracy, precision, recall)
def plot_discrimination_thresholds(model, validation_generator):
# some set up code
...
thresholds = np.linspace(0, 1, 6)
accuracy = []
precision = []
recall = []
for threshold in thresholds:
single_accuracy, single_precision, single_recall = compute_metrics(model, validation_generator, threshold)
accuracy.append(single_accuracy)
precision.append(single_precision)
recall.append(single_recall)
plt.plot(thresholds, precision, label="precision")
plt.plot(thresholds, recall, label="recall")
plt.plot(thresholds, accuracy, label="accuracy")
plt.ylabel('score')
plt.xlabel('threshold')
plt.legend()
Basically it ran in two nested loops. The first loop loops over the thresholds. The nested loop loops over the batches in validation_generator. In that nested loop, it'll collect true positives, true negatives, false positives. Once it has seen all the data, it returns the accuracy, precision and recall for that threshold.
The code runs fine and will display the chart that I was looking for. However it is extremely slow and scales linearly with the number of thresholds. That's what led me to briefly look up how to parallelize the computation for each threshold. See my failed attempt at http://blog.wafrat.com/how-to-compute-in-parallel-in-python/.
O(data)
I didn't look further because I realized that I could optimize this way: instead of looping over validation_generator multiple times, I can go over it only once. For every batch, I can generate the actual prediction for each threshold:
logits = model.predict(x_batch).flatten()
for index, threshold in enumerate(thresholds):
predictions = (logits > threshold) * 1
...
So the main loop becomes the loop over the batches in validation_generator and the nested loop loops over the thresholds. Since the main loop only runs once, the run time doesn't scale with the number of thresholds anymore.
The final version of the code looks like this:
from matplotlib import pyplot as plt
def plot_discrimination_thresholds(model, validation_generator):
is_binary = len(validation_generator.class_indices) == 2
if (not is_binary):
raise Exception('Only binary classifiers are supported')
n_points = 30
thresholds = np.linspace(0, 1, n_points)
true_positives = np.zeros(n_points)
false_positives = np.zeros(n_points)
positives = np.zeros(n_points)
for i in range(len(validation_generator)):
x_batch, y_batch = validation_generator[i]
logits = model.predict(x_batch).flatten()
labels = y_batch
for index, threshold in enumerate(thresholds):
predictions = (logits > threshold) * 1
true_positives[index] += np.sum(predictions[labels == 1])
false_positives[index] += np.sum(labels[predictions == 1] == 0)
positives[index] += np.sum(labels)
# precision[i] = precision at thresholds[i]
precision = true_positives / (true_positives + false_positives)
# Interpret NaN as perfect precision.
precision[np.isnan(precision)] = 1
recall = true_positives / positives
f1 = 2 * precision * recall / (precision + recall)
plt.plot(thresholds, precision, label="precision")
plt.plot(thresholds, recall, label="recall")
plt.plot(thresholds, f1, label="f1")
plt.ylabel('score')
plt.xlabel('threshold')
plt.legend()
Interpreting the chart
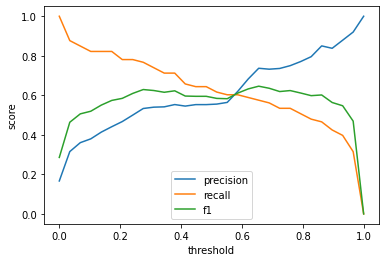
As per the scikit-learn documentation, "Optimizing [the F1 score] produces the best balance between precision and recall.". In the example above, you can see that the maximum F1 score is at threshold 6.5. And even then, precision and recall are not that great. When the model predicts a positive, it is right 75% of the time, and it wrongly classifies as negative 40% of actual positives.