Use TensorBoard in Colab to track the training of a text classification model
I just read Chapter 7 of Chollet's Deep learning with Python, and it introduces TensorBoard as a way to visualize metrics in real-time during training and embeddings.
The goal
In order to try it out, I decided to make a text classification model that predicts the category of a news article. My goal is that at the end, I'll be able to visualize at first glance when my model started overfitting without having to mess with matplotlib. I also want to see in 3D the cloud of words, and see that words of similar category will be close to one another.
Setting up the Model
I used code introduced in an earlier chapter on using Conv1D to train text models:
from keras import datasets
num_words=10000
(x_train, y_train), (x_test, y_test) = datasets.reuters.load_data(num_words=num_words)
from keras import preprocessing
max_length=500
x_train = preprocessing.sequence.pad_sequences(x_train, maxlen=max_length)
x_test = preprocessing.sequence.pad_sequences(x_test, maxlen=max_length)
from keras.utils.np_utils import to_categorical
num_classes=46
y_train = to_categorical(y_train, num_classes=num_classes)
y_test = to_categorical(y_test, num_classes=num_classes)
from keras import layers, models
model = models.Sequential()
model.add(layers.Embedding(num_words, 128, input_length=max_length))
model.add(layers.Conv1D(32, 7, activation="relu"))
model.add(layers.MaxPooling1D(5))
model.add(layers.Conv1D(32, 7, activation="relu"))
model.add(layers.GlobalMaxPooling1D())
model.add(layers.Dense(num_classes, activation="softmax"))
model.summary()
model.compile(loss="categorical_crossentropy", metrics=['acc'])
Running TensorBoard in Colab
In the book, Chollet simply runs tensorboard --logdir hislogdir in the Terminal. However, I'm trying to run it in Colab.
In Colab, to run a command in Terminal, you prefix it with !:
!tensorboard --logdir logs
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.4.1 at http://localhost:6006/ (Press CTRL+C to quit)
However, this won't work because I don't know the IP of the VM running this Colab instance.
A quick search on Google leads to https://www.tensorflow.org/tensorboard/tensorboard_in_notebooks. It turns out there is a Colab extension that lets you run TensorBoard within Colab:
Load the TensorBoard notebook extension
%load_ext tensorboard
%tensorboard --logdir logs
Training the Model
callbacks=[keras.callbacks.TensorBoard(embeddings_freq=1, histogram_freq=1)]
model.fit(x_train, y_train, epochs=30, validation_split=.2, callbacks=callbacks)
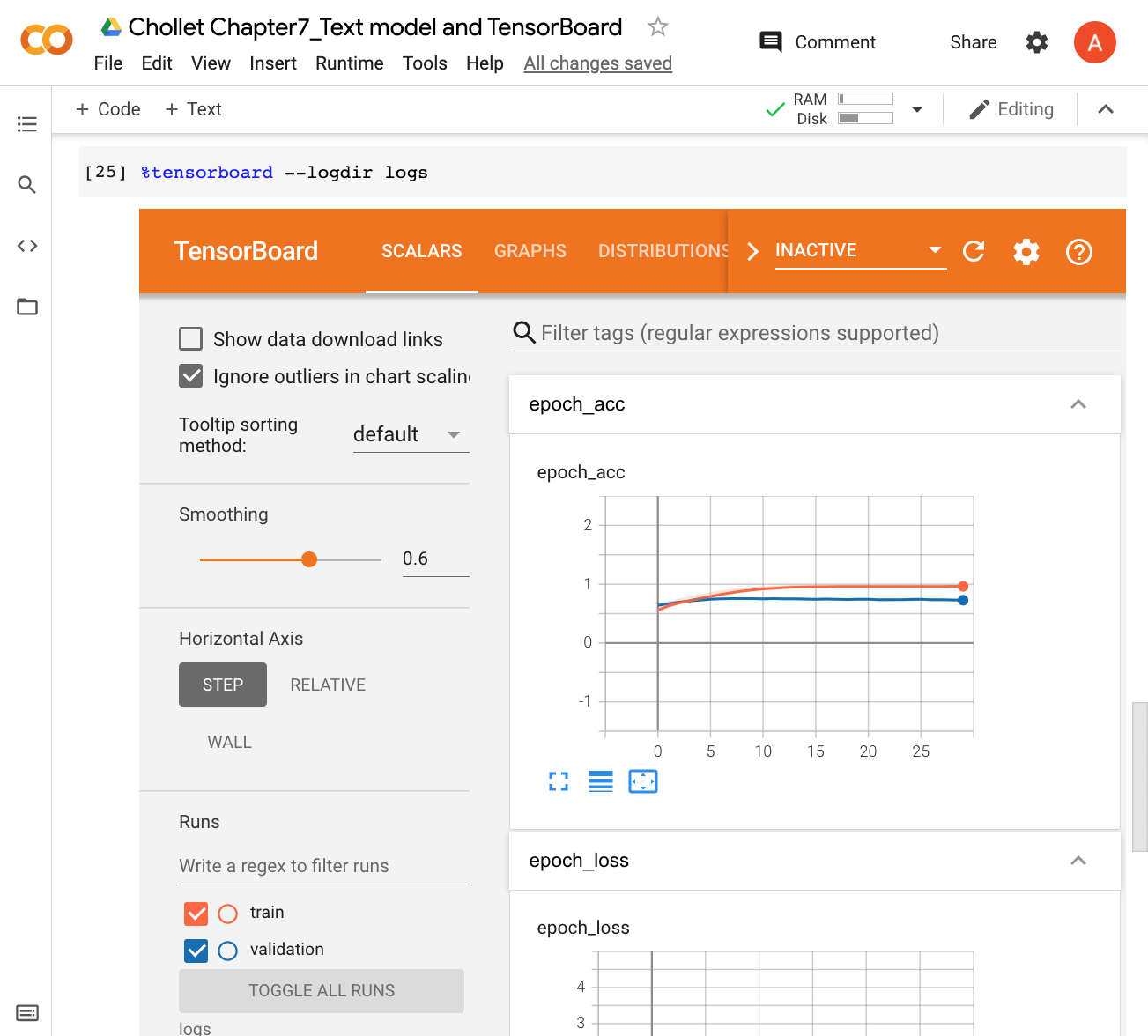
While it ran, I could see the latest state of the metrics charts by clicking the Reload data button in the upper right corner of TensorBoard. At the end of training, here's how my charts looked:
Visualizing embeddings
Browsing tutorials
Finally I wanted to see the clouds of words and how they would be clumped together. The tutorial on TensorBoard built-in Projector plugin shows great looking screenshots: https://www.tensorflow.org/tensorboard/tensorboard_projector_plugin.
However to my surprise, my Projector shows only word indexes instead of the actual words.
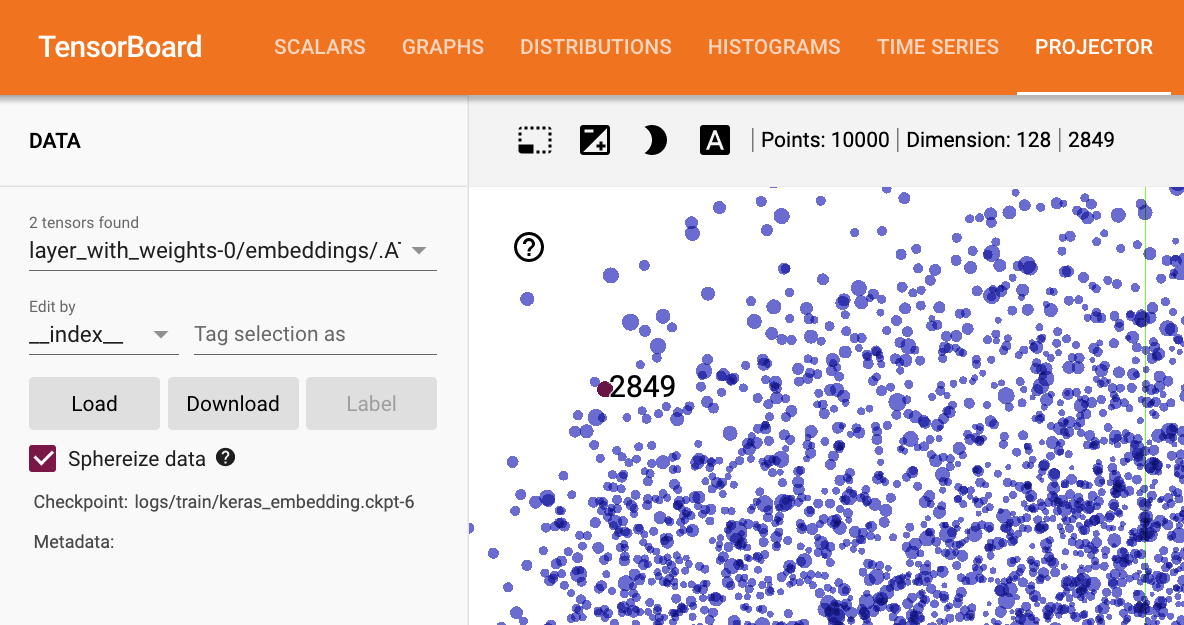
It makes sense since the input data is those word indexes, but there should be an easy way to feed the mapping of word index to actual word.
However, the Projector documentation seems to be broken. Both the online version of the Projector (https://projector.tensorflow.org/) and Keras's documentation on TensorBoard callbacks have broken links to the Projector documentation. So the only way to understand how to generate metadata.csv is to look at sample code.
Luckily https://www.tensorflow.org/api_docs/python/tf/keras/callbacks/TensorBoard lists all the tutorials that use it.
The Projector tutorial shows a snippet of code that prepares metadata.tsv, which you can feed into the plugin:
# Load the data and encoder info
(train_data, test_data), info = tfds.load(
"imdb_reviews/subwords8k",
split=(tfds.Split.TRAIN, tfds.Split.TEST),
with_info=True,
as_supervised=True,
)
encoder = info.features["text"].encoder
# Save Labels separately on a line-by-line manner.
with open(os.path.join(log_dir, 'metadata.tsv'), "w") as f:
for subwords in encoder.subwords:
f.write("{}\n".format(subwords))
# Fill in the rest of the labels with "unknown"
for unknown in range(1, encoder.vocab_size - len(encoder.subwords)):
f.write("unknown #{}\n".format(unknown))
# Set up config
config = projector.ProjectorConfig()
embedding = config.embeddings.add()
# The name of the tensor will be suffixed by `/.ATTRIBUTES/VARIABLE_VALUE`
embedding.tensor_name = "embedding/.ATTRIBUTES/VARIABLE_VALUE"
embedding.metadata_path = 'metadata.tsv'
projector.visualize_embeddings(log_dir, config)
Another tutorial shows how they generate metadata.tsv and vector.tsv: the word2vec tutorial.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0: continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
So it looks like I can just put each word in metadata.tsv.
Trying it out on my Embedding
So I did the same by getting the index, converting word => index to index => word, then writing down each word from index 1 to num_words:
index = datasets.reuters.get_word_index()
index_to_word = {index: word for word, index in index.items()}
with open('./metadata.tsv', 'w') as f:
f.write('oov\n')
for i in range(1, num_words):
word=index_to_word[i]
f.write(word+'\n')
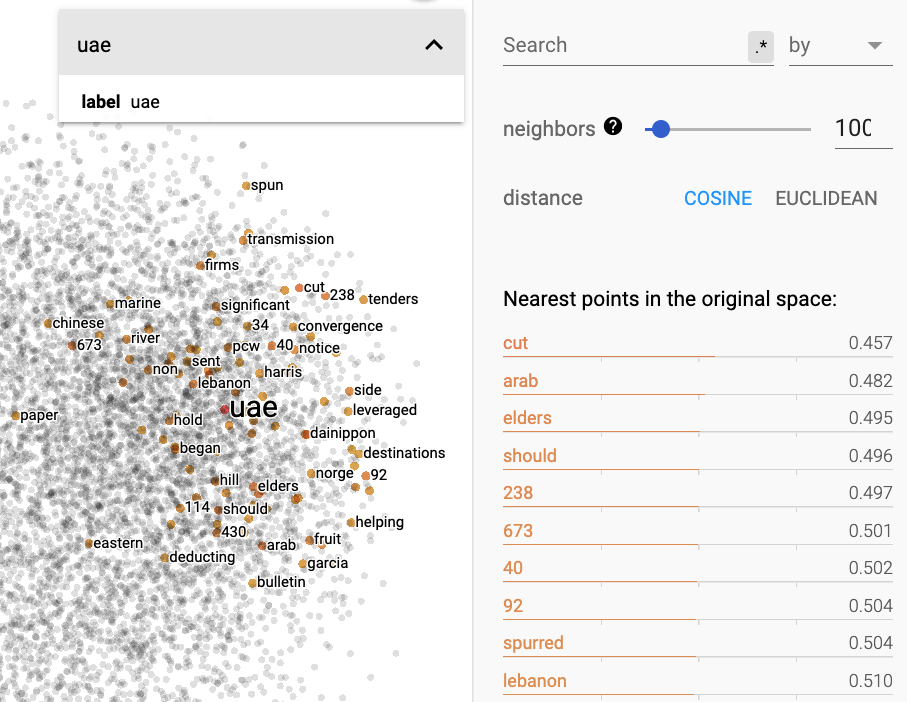
After uploading this file to the Projector plugin, I get this. If I click on the word "uae", it ells me closely related words are cut, arab, elders, should... Not sure why cut and elders should be related, but arab makes sense.
For the word dealerships, it's even more unclear why these words should be related.
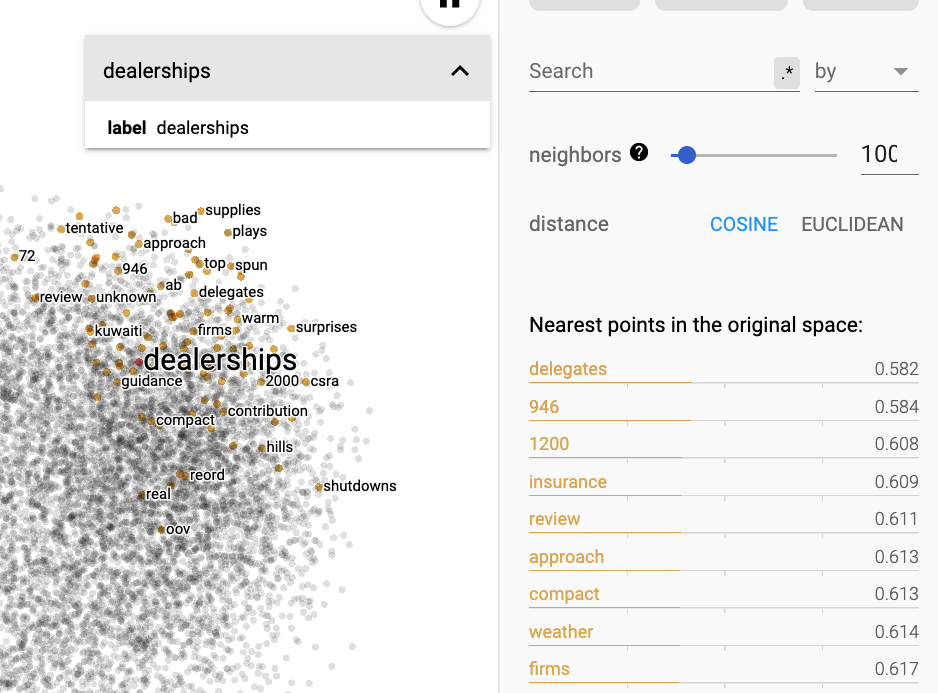
I am actually not sure if I generated the file correctly. Looking up again, it looks like index 0 should be skipped. That means my whole index is off by one line! Let's try again:
with open('./metadata.tsv', 'w') as f:
# skip 0, it is padding
for i in range(1, num_words):
word=index_to_word[i]
f.write(word+'\n')
And here's the new list of words related to dealerships. It doesn't make much more sense either.
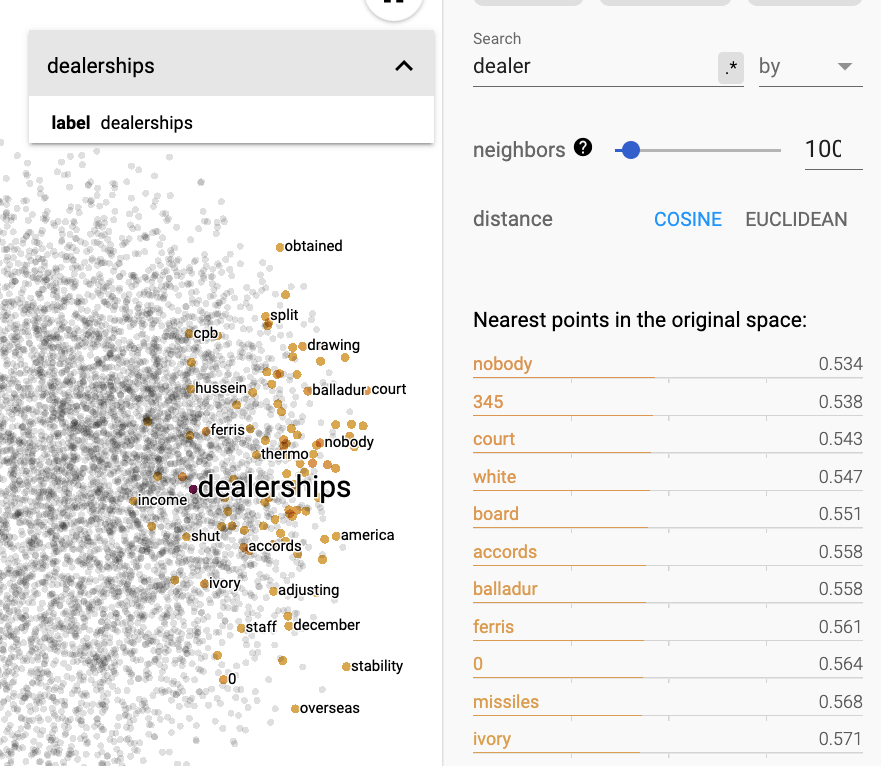
Also uae is now related to other words, the only one which seems to make sense being emirates. It seems more like a fluke than something relevant.
Verifying on example news headlines
To make sure that my indexes are not off, I tried to use the word index on news headlines in the dataset.
def to_words(vector):
return " ".join([index_to_word[index] for index in vector])
to_words(x_train[0])
> the of of mln loss for plc said at only ended said commonwealth could 1 traders now april 0 a after said from 1985 and from foreign 000 april 0 prices its account year a but in this mln home an states earlier and rise and revs vs 000 its 16 vs 000 a but 3 psbr oils several and shareholders and dividend vs 000 its all 4 vs 000 1 mln agreed largely april 0 are 2 states will billion total and against 000 pct dlrs
to_words(x_train[3])
> the in currencies hit firms in has would seven jointly those taiwan 226 over nigel 9 500 s 000 a income csr that at 234 of yielding 7 9 inc british said at those our justice in 24 accepted financing conrac mln a know primary it believe and in case seven york 686 assumes 49 leaves england said conrac two mln by for meetings travel said value recently a of american margarine proved planning loss 90 loss inc can said of yielding plan holding market decline its in way a but 5 will of month in value ago in way as value ucpb of european release for comprised said american cpb preliminary said 018 dw that of global case seven york i 652 extraction process groundwork of in value margarine recently 481 of 564 of amid with for indian by stock 5 name for bangemann planting a in wake pipelines lbs its supply pier 086 said have context behind issuing for arab don't 8 last amid etl in market williams holdings in way share for urge and of at account s end our justice a for of receive of kenya assumes said conrac of of 226 mln in value european of ago winds and leaving by of 5 qtr decline department and yielding plan share for expensive support said nervousness interest next pct dlrs
It turns out there really is an offset I should handle. Reading Chollet's book again, he explains that indexes have to be offset by 3, because 0, 1 and 2 are reserved indexes. I have no idea why the index doesn't reflect that. Anyhow, here's how I handle the offset:
def to_words(vector):
return " ".join([index_to_word[index - 3] if index > 3 else '' for index in vector])
to_words(x_train[0])
> said as a result of its december acquisition of space co it expects earnings per share in 1987 of 1 15 to 1 30 dlrs per share up from 70 cts in 1986 the company said pretax net should rise to nine to 10 mln dlrs from six mln dlrs in 1986 and rental operation revenues to 19 to 22 mln dlrs from 12 5 mln dlrs it said cash flow per share this year should be 2 50 to three dlrs reuter 3
to_words(x_train[3])
> the farmers home administration the u s agriculture department's farm lending arm could lose about seven billion dlrs in outstanding principal on its severely borrowers or about one fourth of its farm loan portfolio the general accounting office gao said in remarks prepared for delivery to the senate agriculture committee brian crowley senior associate director of gao also said that a preliminary analysis of proposed changes in financial eligibility standards indicated as many as one half of borrowers who received new loans from the agency in 1986 would be under the proposed system the agency has proposed evaluating credit using a variety of financial ratios instead of relying solely on ability senate agriculture committee chairman patrick leahy d vt the proposed eligibility changes telling administrator clark at a hearing that they would mark a dramatic shift in the agency's purpose away from being farmers' lender of last resort toward becoming a big city bank but clark defended the new regulations saying the agency had a responsibility to its 70 billion dlr loan portfolio in a yet manner crowley of gao arm said the proposed credit system attempted to ensure that would make loans only to borrowers who had a reasonable change of repaying their debt reuter 3
So the metadata.tsv should be generated like so:
offset=3
with open('./metadata.tsv', 'w') as f:
# skip offset since they are reserved words. later line[k] should show word[k-3]
for i in range(offset):
f.write('\n')
for i in range(1, num_words):
word=index_to_word[i]
f.write(word+'\n')
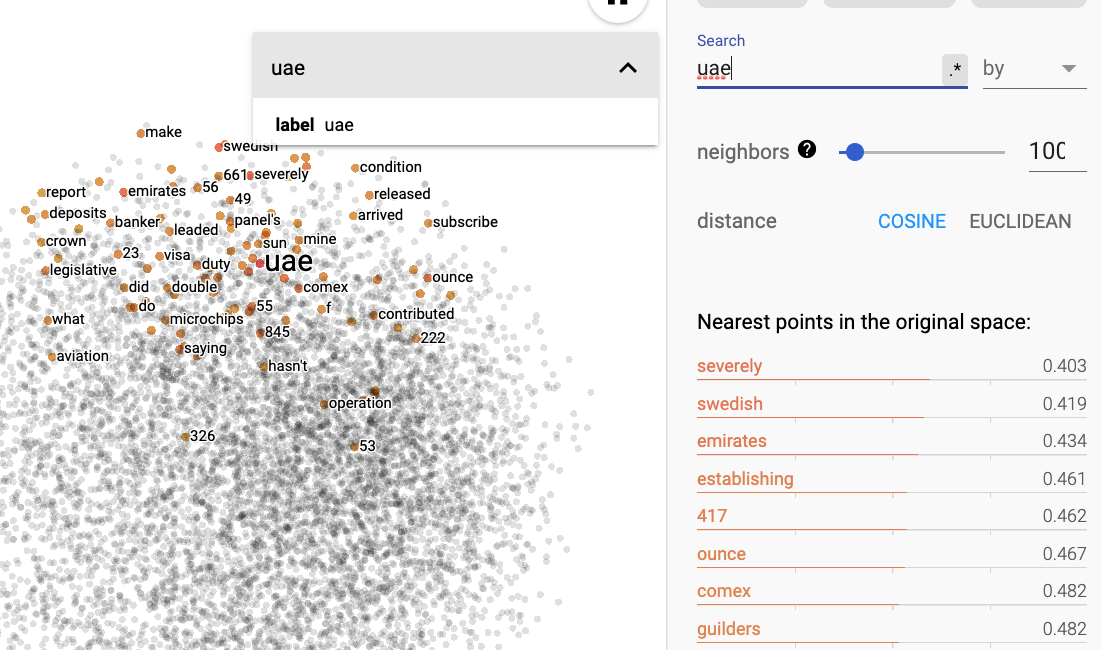
But uae still shows the same correlated words as before:
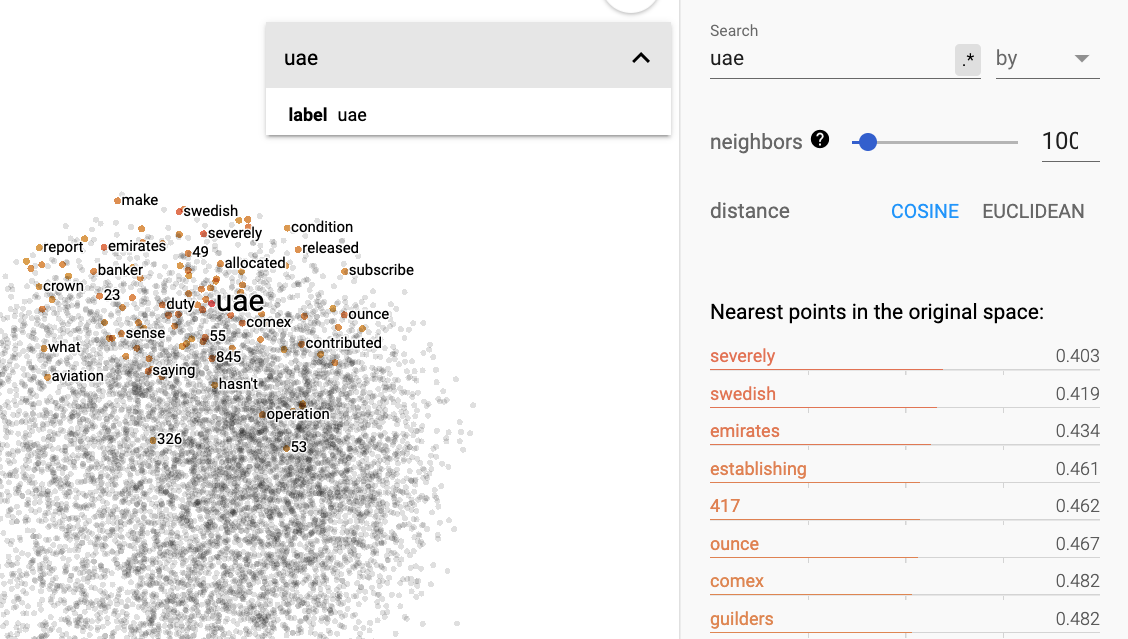
Could it be that since the first three lines are empty lines, projector skips these when processing metadata?

After putting fake data for the first three indexes to make sure they aren't skipped, I load the metadata again.

This time uae is related to odd words.

Same for other words. So it might be that the tutorial was right about only skipping index 0, but I don't understand why that would be, since stringifying news headlines clearly uses an index offset of 3.
One way to know for sure which one is which, is to test on a sentiment analysis problem. Then it should clearly show a group of positive words, and a group of negative words.
This time, using the offset by 3, Projector says:
Number of tensors (10000) do not match the number of lines in metadata (10002).

This suggests again that like the tutorial, we should skip only index 0. This is really confusing.
By skipping only index 0, we get:

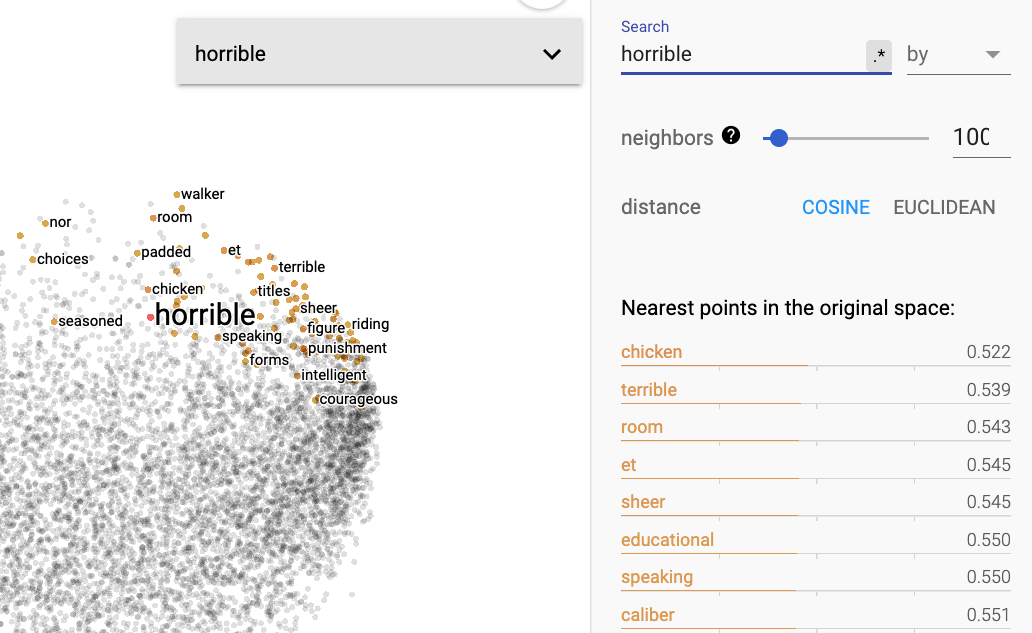
Verifying on a tutorial
Trying on the Projector plugin tutorial, the embedding they train quite clearly groups positive words on one side, and negative words on the other, and words close to fantastic have very small distance compared to mine (.002 vs .5). Finally their index starts with the, so it really does look like indexes should start from 1.
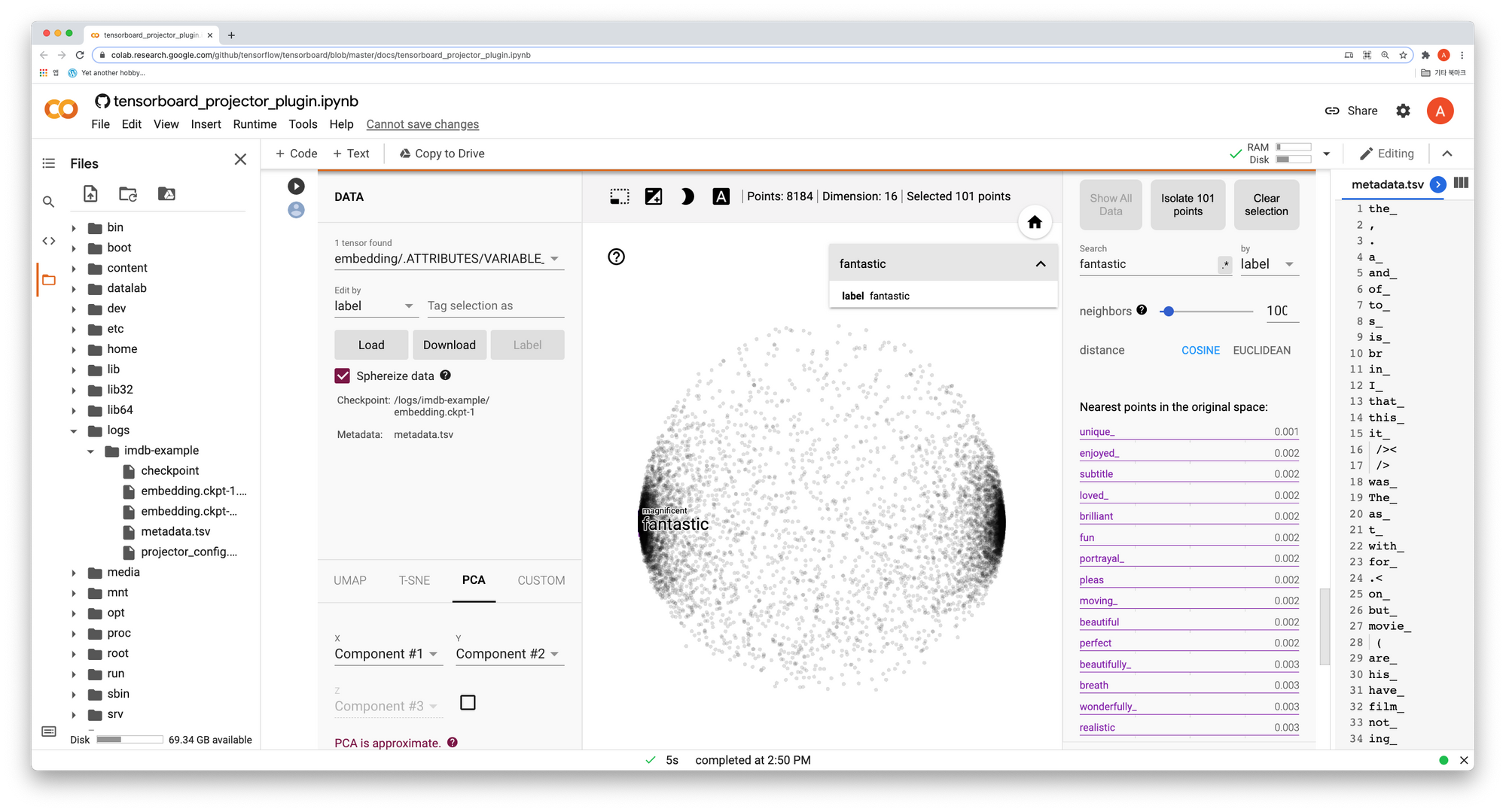
After that I came back to my sentiment analysis model, and trained it for a few more epochs. After 20 epochs instead of 5, the distances between words is down to .05. Still far from .002, but much better than originally.
Anyhow, after lots of wandering, here's how to use the Projector in Colab!